Climate change is a hot topic. It played a part in the debate leading to the recent US presidential election, but its reach and the attention it is getting go way beyond. The global scientific community is not only united in its conviction that anthropogenic climate change is real, but also working in collaboration and heavily relying on data to support its research.
Much of that data comes from organizations based in the US, such as NASA’s NOAA. Donald Trump, the US president elect, has repeatedly expressed his skepticism towards climate change. Could that have an impact on the availability of data for scientific research?
A group of scientists and researchers thinks so, and is working on ways to minimize the impact of such a prospect. Regardless of whether this turns out to be the case, data preservation is a significant topic going forward. We spoke with prominent members of the precarious data movement, as well as with researchers pioneering data preservation technologies, and here is what they had to say.
Precariousness: data as cultural heritage
special feature

The Internet of Things is creating serious new security risks. We examine the possibilities and the dangers.
To begin with, could the prospect of data from organizations such as NOAA vanishing be real? Matt Price & Nick Shapiro, spokespeople for EDGI (Environmental Data & Governance Initiative) think that “this is hard to judge, but we have good reasons to believe at least some and likely a high percentage of data will disappear from public view.” Elaborating on these reasons, they cite:
- The natural turnover of information, which would account for some level of attrition
- The fact that data can be starved out of public view, by cutting off the resources necessary for its upkeep
- Trump administration hostility to climate change research, and to environmental science and the use of evidence and reason in general
- Historical precedents such as the legacy of former Canada administration and the attempted closing of EPA libraries under George W. Bush
Matt Zumwalt, program manager at Protocol Labs, a company developing and advocating a new distributed protocol for the web, argues that “It’s not only the data that are precarious. The entire web is a precarious system because it’s structured as a centralized network. This scramble to save climate data is just the latest symptom of the underlying disease of centralization. The more valuable and central these data become, the more expensive and painful it will be to continue relying on a centralized network.”
EDGI:
“would suggest that scientific data is precisely a form of cultural heritage which belongs to all of us and to our descendants. While the scientific enterprise has never been perfect, it has promoted a principle vital to our societies: that anyone can propose theoretical accounts or make sense of empirical data, and be judged only on the basis of their arguments.
Without evidence, those arguments can’t be made, and our common heritage of reasoned discourse disappears. So the duty to preserve data is, in our view, as strong as the duty of cultural preservation.”
Zumwalt was even more acute: “Destroying climate data is the equivalent of a book burning.”
![]()
If data is the new cultural heritage, what does that make removing access to data?
Preservation: data distribution and authenticity
But does this particular case point towards a need for change on the institutional level, and does that relate to technological capabilities? Some of NOAA’s data was already hosted in the public cloud for free. And if successful, the Climate Mirror initiative that EDGI is part of will also host some of that data in servers of universities and research institutions. In both cases however, that mitigates, but does not eradicate the issue.
Hosting data comes at a cost. Cloud providers like AWS have chosen to foot this bill as they expect that increased demand for computation on that data, also provided by them under commercial terms, will help them cover the associated cost.
Another related issue is the authenticity of data. For data hosted by NOAA for example, the assumption is that they are authentic as they are published by a credible agency. But if the same data is copied and hosted by a different party, or even if the original publisher for some reason loses its credibility, it is not inconceivable that data could be tampered with.
Advances in distributed and peer-to-peer technology and the commoditization of storage and compute may offer some solutions there. The Internet Archive recently put out a call for a distributed web. Potential solutions could include new protocols such as IPFS or Blockchain, databases based on principles such as immutability and distribution, or personal cloud solutions like OwnCloud and NextCloud.
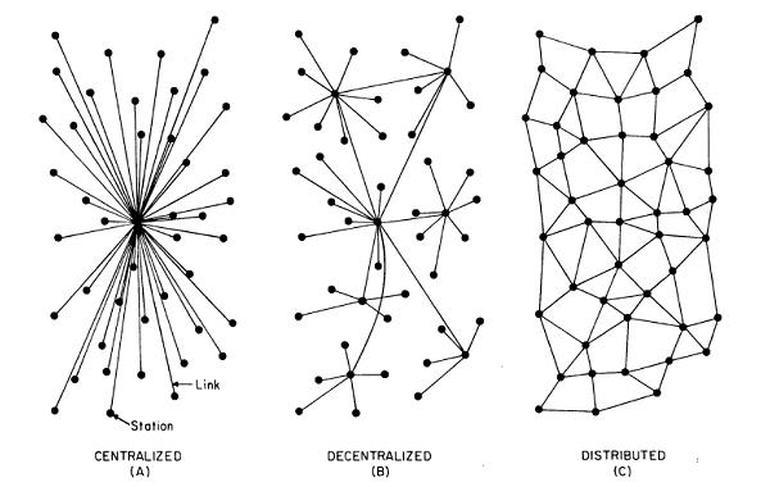

Are our data architectures centralized, decentralized, or distributed?
EDGI:
“Has come to realize that this project opens on to an enormous question about the future of the Internet and data in general. The sudden shift in expectations brought on by a single election in one country highlights the fragility of our current data management strategies.
If governments and large institutions can’t be relied on to preserve the public good — and in the long run, they probably can’t be — then we need to engage in a very serious rethinking of the foundations of the Internet. These options are very much in the forefront of our internal discussions.”
For Zumwalt:
“Institutions that think of themselves as stewards of knowledge should be using decentralized approaches to publish and preserve data. These technologies make it possible for data to pass through many hands without losing integrity. We need to leave the door open for anyone to become stewards of information at any time. Remember, we wouldn’t have copies of Plato’s works today if people had relied exclusively on the Library of Alexandria, or even the whole Roman empire, to hold those texts.
Location is a bad proxy for authenticity. Servers can be hacked and organizations can be forced to turn off servers (or to intentionally corrupt their contents). If you want to publish data in a way that ensures its integrity and allows everyone to validate its authenticity , you should be publishing the cryptographic hashes of your data and using a content-addressed protocol like IPFS to publish the data rather than using a location-addressed protocol like HTTP.”
Going forward: data, tools, protocols, and cultural shift
As Apple’s CEO Tim Cook put it, yelling is not enough. Are these solutions, radical and exotic as they may sound, ready for prime time? The Climate Mirror initiative represents a great challenge, as well as a great opportunity: if they can make it there, they’ll make it everywhere. There seems to be an emergent ecosystem molding in this space, with solutions forming synergies and people behind them willing to point them out and work with each other.
Trent McConaghy, founder and CTO of BigchainDB, exemplified this by commenting “this could be big. BigchainDB+IPDB (for structured data) and IPFS+FileCoin (for data blobs) could make all the difference. We’re not in a position to build the apps ourselves, as we must focus on rolling out the underlying infrastructure (BigchainDB+IPDB). But we’re happy to provide support to people building the apps on top, especially for super important ones like this.”
Physical access barriers aside however, data is scattered across various repositories, encoded in various formats, typically needs manual processing, does not allow for querying, aggregation and cross-linking, and lacks metadata and context that would make it easier to understand and process. This makes it hard even for domain experts to use that data and get insights, let alone for the general public. Consequently, driving at disputable conclusions may be inevitable.
Could data format standardization, metadata, documentation, and, ultimately, platforms for accessing environmental data that are built with a consumer-oriented philosophy help there? And what about data collection? Even if existing data is preserved via the collective efforts of people involved in this initiative, the argument goes, if data collection efforts from this point on are undermined, climate change research would be hampered significantly on a global scale.
One potential way of dealing with this could be crowdsourcing climate data collection. Although there are known issues related to data quality for crowdsourced data, there are also potential solutions put forward and this paradigm is already in use for commercial applications such as weather forecast.
Crowdsourcing cannot at this point provide high quality and precision data using specialized equipment — but could it complement data from research and scientific agencies, and what would be needed to involve more people in crowdsourcing and make the best use of collected data?
For Zumwalt:
“This particular set of issues is just the latest manifestation of the crisis of reproducibility that’s currently gripping world of peer-reviewed research. Content-addressing, which lies at the core of decentralized technologies like git, BitTorrent and IPFS, is an absolutely essential tool for addressing these goals of making research reproducible and making data analysis horizontally scalable on a global scale. Specifically regarding data formats and cross-linking, we have developed IPLD as a data format and path scheme that allows you to generically traverse any content-addressed data.
Crowdsourcing is about participating in producing data. But to truly work on a global scale we also need structures for everyone to participate in holding that data, and to create and exchange multiple “forks” of data, in the same way that git allows developers to track multiple forks of software.
This will make the data infrastructure resilient, and it will force us to grapple with questions of attribution, authority, authenticity and trustworthiness. The existing centralized approach to data collection, data management and publication of research has allowed us to operate under the illusion that those are solved problems. Clearly they’re not.”
For EDGI:
“These technical considerations are essential but not sufficient. We need a fundamental reversal in the momentum of public discourse, away from a solipsistic scepticism and towards a collective, reinvigorated, search for inclusive common standards of evidence and verification. The tools you describe can provide immense assistance here, but in our view the underlying cultural shift is more fundamental, and will have to be carried out through hard, sustained, grass-roots effort.
It will take tremendous efforts to replicate the co-ordinated data-gathering that governments and other large institutions have been able to provide. However, if it comes to that, we will need to build on the kind of efforts that citizens have made since 1970’s when they found themselves abandoned by governmental authorities. With contemporary information technologies, it should be possible to find solutions to the two major difficulties of previous efforts — standardization of observation protocols, and amalgamation of results.
Projects like Galaxy Zoo and Folding@Home have already shown that Internet-mediated crowdsourcing can be highly effective in some situations. We would need to develop a set of protocols, and we would need to harness the efforts of many, many people — but with the urgency of the issue, we might have a fighting chance of succeeding. While crowdsourcing may be possible (and is already a silent backbone of meteorological and ornithology) it should not be on civil society to preform these tasks without government support.”
Disclaimer: Interviews with EDGI’s Matt Price (director of digital development), Nick Shapiro (executive director) and Matt Zumwalt were conducted over email and have been edited for brevity and clarity. The unabridged version of questions sent and answers received can be found here.